程式設計大概是世界上最容易在網路上找到答案的領域了,
奇妙的是有關於生物資訊(生資)的程式設計與分析,
在中文的世界卻寥寥無幾。
對從 Wet Lab (生物實驗)跳到 Dry Lab (生資分析)的你來說,
學習充滿邏輯的程式語言是一個坑,
學習充滿生物意義的資料結構更是一個坑。
而從資訊領域跳到生資分析的你來說,
看著莫名其妙跟我不熟的序列與生物知識,
難懂 Wet Lab 的他們想要我把資料視覺化成什麼樣子。
而下列的式子仍舊是不變的道理 :
程式=演算法+資料結構
只是不小心撒上了一些生物 :
生資分析=生物意義+演算法+資料結構
於是本系列文章就這麼誕生了!
以 16S rRNA 微生物組定序分析為基礎,
追完這些文章或許沒辦法讓你變成高手,
但是希望能讓你獲得最最最基礎的能力,
在充滿原文的知識海裡遨遊時能更得心應手。
本系列以指令操作分析為主,先學習使用別人的程式,待你熟悉分析的產物之後,
就能站在巨人的肩膀上,再自行學習 Python, R, MATLAB 等技能,讓資料的視覺化更完美。
通常生資分析所需要的運算資源甚多,
Linux純指令介面少了圖形化介面的資源運算,運算效率較佳,適合大量運算的工作,
實務上多半以遠端連線到Linux伺服器/工作站。
畢竟你家通常不會有一台好幾十萬的電腦,
我說通常。
至少需要有高中選修生物或大一普通生物學的基礎知識。
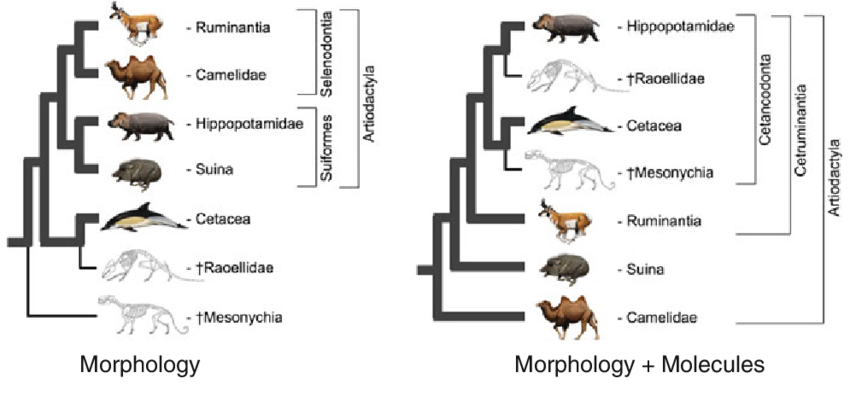
親緣關係樹圖。型態與分生都能繪製演化樹,參考的基準不同,演化樹也會有所異同,而在微生物的世界多以分生(序列差異)為基準。(Bibi, F., & Métais, G., 2016)
說要會 Git 版本控制 (Version control) 就太殘忍了,至少要會以下事情 :
學習地圖的存在可以幫助你更了解整個知識架構 :
本篇文章同步刊載於科學毛怪部落格 PetSci Blog。

